
Kafka是大型架构核心,下面我详解Kafka高吞吐技术@mikechen
顺序写入与零拷贝机制
Kafka 的高吞吐并非依赖单一的“魔法”,而是 “磁盘顺序写入” 奠定了高 I/O 性能的基础。
“零拷贝” 优化了网络传输效率,“批量处理” 减少了通信开销。
而 “分区并行” 实现了水平扩展,最终共同构建了一个能够高效处理大规模数据流的系统。

Kafka 将每个分区的数据,以追加(append-only)方式写入磁盘文件,并按固定大小切分为若干日志段。
追加写入避免了随机写导致的磁盘寻址开销,能够高效利用操作系统页缓存与磁盘顺序写带宽。
日志段机制便于批量落盘与旧数据清理,从而降低 I/O 负担并提升持续写入吞吐。
分区化与并行处理
Kafka 的主题(Topic),被分为多个 分区(Partition),每个分区独立存储、独立消费。
分区并行写入:Producer 可同时写入多个 Partition,Broker 间并行处理。
Consumer Group 并行消费:多个消费者分摊不同分区,实现水平扩展。
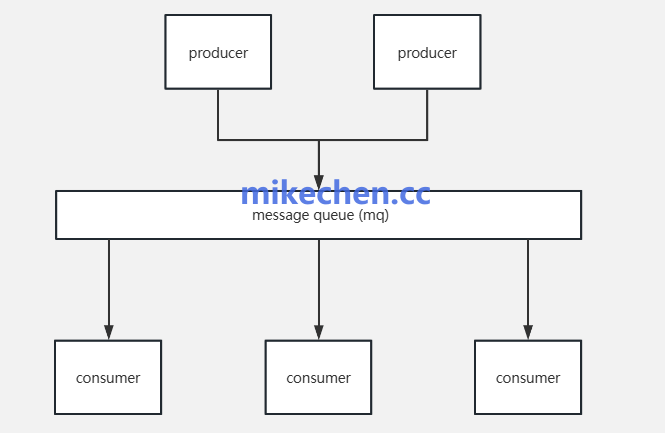
Broker 集群分布式部署:Topic 可横向扩展,吞吐随节点线性增长。
写入与消费均可并行处理,充分利用多核与多节点。
可通过增加分区数量来水平扩展吞吐。
每个分区独立顺序写入,保证高性能与局部有序性。
批量传输与压缩
Kafka 利用操作系统提供的零拷贝(sendfile 等),技术在网络传输时避免从内核空间到用户空间的额外数据拷贝。
从而,显著降低了 CPU 占用并提高网络带宽利用率。
此外,Kafka 使用批量(batch)发送与压缩(compression)策略。
将多条消息合并为大数据块传输,减少每条消息的网络与协议开销。

异步复制与可配置的持久化策略
Kafka 的副本机制,通过主副本(leader)和跟随者(follower)实现数据冗余。
但允许在不同一致性,与持久化策略下权衡吞吐、与可靠性。
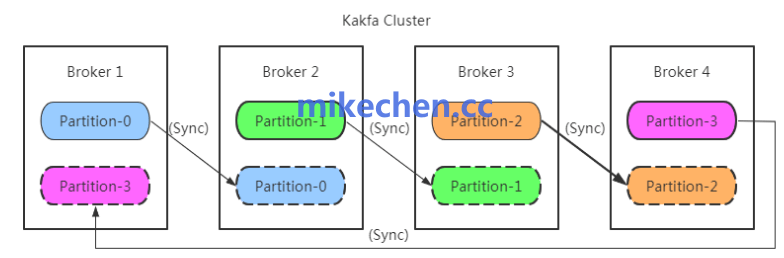
异步复制与可配置的 ack 策略,使得在追求更高吞吐时可以降低同步等待延迟。
与此同时,合理设置批次大小、 linger.ms、flush 策略,及分区副本数,能够在保证可接受可靠性的前提下最大化吞吐。