
一个数据密集型的应用,如何应对数据量及数据复杂度激增,以及数据变化速率变快?
使用 Kafka 来解决这些问题,能起到非常好的效果。
例如:针对数据量激增,Kafka 通过有效隔离上、下游业务,将上游突增的流量先缓存起来,再用平滑的方式,将流量传导到下游的子系统中,从而避免了流量的不规则冲击。
如果你是大数据工程师,又或想要成为架构师,那 Kafka 一定要深入学习掌握。
我最新总结的这份 Kafka 学习进阶路线及资料,包含了 Kafka 涉及的所有核心知识点,可以用来参考学习、构建知识体系、复盘技术栈。
Kafka 学习进阶路线
把图谱放大,就能看清楚了。
《Kafka 学习进阶路线》高清图谱,到文末直接获取。
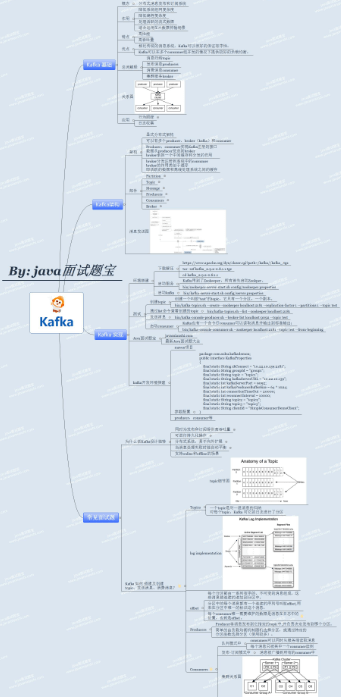
Kafka 学习进阶资料
基础
- 什么是Kafka
- 为什么要使用 Kafka
- Kafka 为什么那么快
- Kafka 高效文件存储设计特点
- Kafka与传统MQ消息系统的主要区别
- Kafka的分区数是不是越多越好
- 创建topic时,如何选择合适的分区数
- Kafka中是怎么体现消息顺序性的
- Kafka中的消息是否会丢失和重复消费
- Kafka中的分区器、序列化器、拦截器的处理顺序是什么
- Kafka不支持读写分离的原因是什么
- Kafka的message格式是什么样的
- Kafka中的ISR、AR是什么,ISR的伸缩呢
- 什么情况下,一个 Broker 会从 ISR 中踢出去
- Kafka中的HW、LEO、LSO、LW等分别代表什么
- Kafka中的 Broker 的作用是什么
- Kafka中 consumer group 是什么
- Kafka 消息是采用 Pull 模式,还是 Push 模式
- Kafka 判断一个节点是否还活着,需要具备哪些条件
- Kafka unclean配置代表啥,对spark streaming消费有什么影响
- Kafka producer打数据,ack为 0,1,-1 时代表什么?设置-1时,leader在什么情况下会认为一条消息commit了
- Consumer消费Parition的分配策略
- 使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑
- 如果leader crash时,ISR为空怎么办
事务
分区策略
数据保留/数据传输
应用
其它
《Kafka 学习进阶路线》高清知识全景图获取方法
网盘链接经常失效,扫码加我微信 javamianshi66 ,发送通关暗号 kafka ,即可免费获取。
未来一起学习、一起刷题。
谢谢关注 Java面试题宝,我是爱分享的程序员宝妹儿。
免费开源分享,不求打赏,觉得有用的话,请顺手【点赞+评论+转发】送个精神鼓励,谢谢支持。
—end—
Java 工程师高薪必备资料: