
参考答案
一、分库分表的实现方案
有如下两种:
1. 增加一个中间层,中间层实现 MySQL 客户端协议,可以做到应用程序无感知地与中间层交互。由于是基于协议层的代理,可以做到支持多语言,但需要多启动一个进程、SQL 的解析也耗费大量性能、由于协议绑定仅支持单个种类的数据库库。
2. 在代码层面增加一个路由程序,控制对数据库与表的读写。路由程序写在项目里,与编程语言绑定、连接数高、但相对轻量(比如 Java 仅需要引入 SharingShpere 组件中 Sharding-JDBC 的 jar 即可)、支持任意数据库。
二、分库分表的实现配置
以 Sharding-JDBC 实现分库分表为例子。
1、数据库环境
ds0:172.31.32.184 ,ds1:172.31.32.234 ,用作分库。
2、在 ds0 和 ds1 库中建表,t_order0 和 t_order1 用做分表。
create table t_order0( order_id int primary key, user_id int, goods_id int, goods_name varchar(200) ); create table t_order1( order_id int primary key, user_id int, goods_id int, goods_name varchar(200) );
3、新建 maven 项目,添加依赖
<!-- 当前最新版 sharding-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.1.1</version>
</dependency>
<!-- 结合官方文档使用了 HikariCP 数据库连接池 -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.5</version>
</dependency>
<!-- MySQL 8.0.21 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
4、数据源连接工具类,使用 HikariCP 数据库连接池
import javax.sql.DataSource;
public final class DataSourceUtil {
private static final int PORT = 3306;
/**
* 通过 Hikari 数据库连接池创建 DataSource
* @param ip
* @param username
* @param password
* @param dataSourceName
* @return
*/
public static DataSource createDataSource(String ip, String username, String password, String dataSourceName) {
HikariDataSource result = new HikariDataSource();
result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());
result.setJdbcUrl(String.format("jdbc:mysql://%s:%s/%s?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8", ip, PORT, dataSourceName));
result.setUsername(username);
result.setPassword(password);
return result;
}
}
5、测试代码
测试逻辑:
- 使用数据源工具类,新建 ds0 和 ds1 库的数据源。
- 配置 t_order 表的规则,ds$->{0..1}.t_order$->{0..1}。
- 配置分库分表的规则,分库根据 ds 拼接上 t_order 的 user_id 字段值 对 2 取模的值(ds${user_id % 2});分表根据 t_order 拼接上 order_id 字段值 对 2 取模的值(t_order${order_id % 2})。
- 测试 insert 不同的 user_id 和 order_id 是否会按规则插入不同的库和表。
- 查询 user_id = 2 的数据,看看是否正常查出。
import org.apache.shardingsphere.api.config.sharding.ShardingRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.TableRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.strategy.InlineShardingStrategyConfiguration;
import org.apache.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
/**
* 测试 ShardingSphere 分表分库
*/
public class Test {
//DataSource 0
private static DataSource ds0 = DataSourceUtil.createDataSource("172.31.32.234", "root", "constxiong@123", "constxiong");
// DataSource 1
private static DataSource ds1 = DataSourceUtil.createDataSource("172.31.32.184", "root", "constxiong@123", "constxiong");
public static void main(String[] args) throws SQLException {
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds0", ds0);
dataSourceMap.put("ds1", ds1);
// 配置Order表规则
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("t_order", "ds$->{0..1}.t_order$->{0..1}");
// 配置分库 + 分表策略
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order${order_id % 2}"));
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
// 获取数据源对象
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());
Connection connection = dataSource.getConnection();
Statement statement = connection.createStatement();
statement.execute("insert into t_order value(1, 1, 1, '电视机')");
statement.execute("insert into t_order value(2, 1, 2, '可乐')");
statement.execute("insert into t_order value(3, 2, 8, '空调')");
statement.execute("insert into t_order value(4, 2, 9, '手机壳')");
statement.execute("select * from t_order where user_id = 2");
ResultSet resultSet = statement.getResultSet();
while (resultSet.next()) {
System.out.printf("user_id:%d, order_id:%d, goods_id:%d, goods_name:%s\n",
resultSet.getInt("user_id"),
resultSet.getInt("order_id"),
resultSet.getInt("goods_id"),
resultSet.getString("goods_name")
);
}
}
}
6、结果
数据按照分库分表的规则插入对应的数据库与表中。
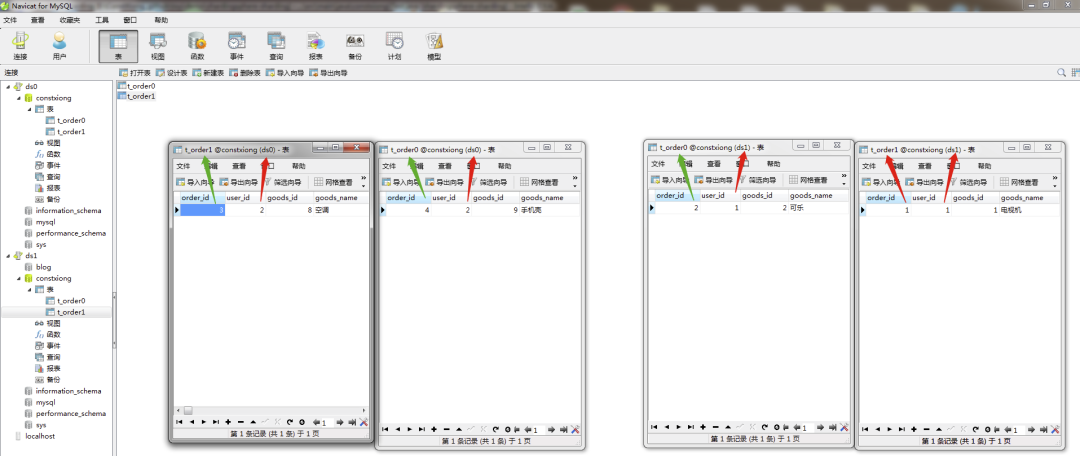
user_id = 2 数据代码查询:
user_id:2, order_id:4, goods_id:9, goods_name:手机壳 user_id:2, order_id:3, goods_id:8, goods_name:空调
以上,是MySQL面试题【如何实现分库分表】的参考答案。
输出,是最好的学习方法。
欢迎在评论区留下你的问题、笔记或知识点补充~
—end—