
本文主要介绍哈希索引的概念、6个局限性、4个常见应用场景,并通过图解、代码示例,力求剖析到位。
这是互联网某大厂的一道面试题:
哈希索引的查询效率更高,还有时间及空间复杂度的优势。为什么不全部用哈希索引,还要使用 B 树或 B+ 树索引呢?
其实这道题真正要问的是“哈希索引的局限性是什么?”。这道题目,大多同学都能回答上几点,但想要超出面试官的预期,就要更进一步才行。
认真看完本文,争取在下次面试中,交上满分答案。
PS.
刚结束的 MySQL Binlog从基础到精通,24张图全面总结、及 MySQL 事务从基础到精通,50+张图彻底吃透,宝子们的反馈还不错。
宝妹儿已将内容更新到《MySQL 大厂高频面试题大全》PDF了,方便系统学习、面试通关。
《MySQL 大厂高频面试题大全》PDF,已收录100+道真题,一共78页,近50000字,文末自取。
吃透它,足以应付MySQL面试。

1. 哈希索引是什么
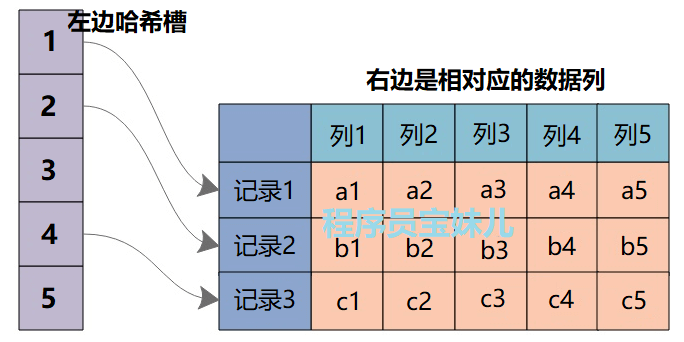
在 MySQL 中,哈希索引是一种以键-值(key-indexed)存储数据、基于哈希表实现的索引结构,只有精确匹配索引所有列的查询才能生效。
由于哈希索引只需要存储对应的哈希值和相关数据行的指针,这种相对紧凑的索引结构,赋予了它快速数据检索的能力。
一旦场景适用哈希索引,它带来的性能提升就会非常显著。
哈希索引的结构:
但是,哈希索引也有自身的一些局限性,哈希索引限制很多,只适用于限定的场景。
2. 哈希索引的局限性
哈希索引的局限性,主要如下:
- 哈希冲突
- 可能占用很多内存空间
- 不适用于范围查询
- 不适用于模糊查询
- 无法支持数据的排序操作
- 不支持多列复合索引的最左匹配原则
下面,逐一解析。
2.1 哈希索引可能会哈希冲突
哈希码可能存在哈希冲突,如果 hash 算法设计不好,就会产生碰撞,碰撞过多时,性能也会变差。
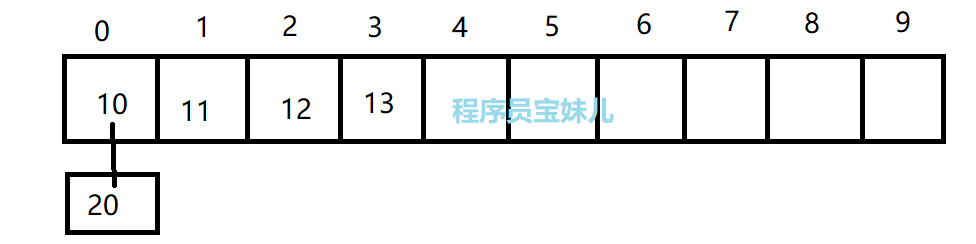
示例:

假设,存储的数 n,存储的索引值 = n % 10 。
现在,我们要将 20 存入到这个表中,计算出的键值为 0。
由于这个位置已经有相同的数据了,因此发生了哈希冲突。
解决哈希冲突最常用的两个方法:
1)链表法
链表法简单易实现,适用于大多数情况,最常用,也最为重要。
- 每个桶维护一个链表或其他数据结构(如数组),用于存储所有映射到该桶的键值对。
- 当发生哈希冲突时,新的键值对被插入到相应桶的链表中,而不是覆盖旧的值。
但是,当链表变得很长时,性能会下降。
示例:沿用上面图例,我们把哈希表的节点当做一个链表的头,将 20 存入哈希表。
2)开放地址法
开放地址法通常用于内存更为有限的情况。它可以避免链表的使用,节省内存。
- 当发生哈希冲突时,新的键值对尝试存储在下一个可用的桶中,而不是使用链表。
- 这个过程可以采用不同的探测方法,如线性探测、二次探测、双重哈希等,以寻找下一个可用的桶。
但是,它需要更复杂的逻辑来解决冲突。
2.2 哈希索引可能占用大量内存
哈希索引不能避免全表扫描,它需要事先确定桶的数量,占用内存空间。
示例:
创建一个哈希索引,并插入一些数据。
import java.util.HashMap;
public class HashIndexMemoryDemo {
public static void main(String[] args) {
// 创建一个哈希索引,假设初始桶的数量为5
HashMap<Integer, String> hashIndex = new HashMap<>(5);
// 插入一些数据
hashIndex.put(101, "Alice");
hashIndex.put(102, "Bob");
hashIndex.put(103, "Charlie");
hashIndex.put(104, "David");
hashIndex.put(105, "Eve");
// 尝试插入更多数据,数据量变大
// 这可能导致哈希冲突,也可能需要重新调整索引
hashIndex.put(201, "Frank");
hashIndex.put(202, "Grace");
hashIndex.put(203, "Hank");
// 尝试插入更多数据,数据量变大
// 这再次可能导致哈希冲突,也可能需要重新调整索引
hashIndex.put(301, "Isabella");
hashIndex.put(302, "Jack");
hashIndex.put(303, "Kate");
// 在数据量变大的情况下,哈希索引可能需要重新调整
// 这里简单地将哈希索引重新创建为具有更大容量的新索引
// 实际上,需要重新计算哈希值和重新插入数据,这里仅演示概念
int newCapacity = 10;
HashMap<Integer, String> newHashIndex = new HashMap<>(newCapacity);
for (Integer key : hashIndex.keySet()) {
String value = hashIndex.get(key);
newHashIndex.put(key, value);
}
// 更新哈希索引
hashIndex = newHashIndex;
System.out.println("数据量变大后重新调整哈希索引的容量为 " + newCapacity);
}
}
随着数据的不断插入,数据量就会变得很大。
此时,就需要重新调整索引,增加桶的数量,以容纳更多数据。
2.3 哈希索引不适用于范围查询
哈希索引只支持等值比较。例如,使用=,IN( )和<=>。
示例:
创建一个哈希索引,存储了学生姓名和分数,现在执行一个范围查询,查找分数在 80 到 90 之间的学生。
import java.util.HashMap;
public class HashIndexRangeQueryDemo {
public static void main(String[] args) {
// 创建一个哈希索引,存储学生姓名和分数
HashMap<String, Integer> hashIndex = new HashMap<>();
// 插入一些学生信息
hashIndex.put("Alice", 85);
hashIndex.put("Bob", 92);
hashIndex.put("Charlie", 78);
hashIndex.put("David", 95);
hashIndex.put("Eve", 88);
hashIndex.put("Frank", 89);
// 尝试执行范围查询,查找分数在80到90之间的学生
// 由于哈希索引只支持等值比较,无法进行范围查询
int startScore = 80;
int endScore = 90;
System.out.println("尝试执行范围查询,查找分数在 " + startScore + " 到 " + endScore + " 之间的学生:");
for (String name : hashIndex.keySet()) {
int score = hashIndex.get(name);
if (score >= startScore && score <= endScore) {
System.out.println(name + ": " + score);
}
}
System.out.println("由于哈希索引不支持范围查询,需要遍历所有数据进行筛选,性能较差。");
}
}
由于哈希索引只支持等值比较,无法直接执行范围查询。
必须要遍历所有的键值对,并逐个检查分数是否在指定范围内,这样就导致了性能下降。
2.4 哈希索引不适用于模糊查询
哈希索引无法高效处理模糊查询,例如使用 LIKE 操作符。
示例:
创建一个哈希索引,存储了用户姓名和邮箱地址,现在执行一个模糊查询,查找邮箱地址中包含 “example.com” 的用户。
import java.util.HashMap;
public class HashIndexFuzzyQueryDemo {
public static void main(String[] args) {
// 创建一个哈希索引,存储用户名和邮箱地址
HashMap<String, String> hashIndex = new HashMap<>();
// 插入一些用户信息
hashIndex.put("Alice", "alice@example.com");
hashIndex.put("Bob", "bob@example.com");
hashIndex.put("Charlie", "charlie@example.com");
hashIndex.put("David", "david@example.com");
// 尝试执行模糊查询,查找邮箱地址中包含 "example.com" 的用户
// 由于哈希索引只支持等值比较,无法高效处理模糊查询
String searchPattern = "example.com";
System.out.println("尝试执行模糊查询,查找邮箱地址中包含 \"" + searchPattern + "\" 的用户:");
for (String username : hashIndex.keySet()) {
String email = hashIndex.get(username);
if (email != null && email.contains(searchPattern)) {
System.out.println(username + ": " + email);
}
}
System.out.println("由于哈希索引不支持模糊查询,需要遍历所有数据进行筛选,性能较差。");
}
}
哈希索引只支持等值比较,无法直接执行模糊查询。
因此,必须遍历所有的键值对,并逐个检查邮箱地址是否包含指定的字符串。
将导致性能下降,特别是在大数据集的情况下。
2.5 无法支持数据的排序操作
哈希索引中存放的是经过哈希计算之后的哈希值,哈希值的大小关系,并不一定和哈希运算前的键值完全一样。
因此,数据库无法利用索引的数据来避免任何排序运算。
示例:
创建一个哈希索引,存储了学生姓名和分数,然后对学生分数进行排序。
import java.util.HashMap;
import java.util.Map;
import java.util.stream.Collectors;
public class HashIndexSortingDemo {
public static void main(String[] args) {
// 创建一个哈希索引,存储学生姓名和分数
HashMap<String, Integer> hashIndex = new HashMap<>();
// 插入一些学生信息
hashIndex.put("Alice", 85);
hashIndex.put("Bob", 92);
hashIndex.put("Charlie", 78);
hashIndex.put("David", 95);
hashIndex.put("Eve", 88);
hashIndex.put("Frank", 89);
// 尝试对学生分数进行排序
// 由于哈希索引中存放的是哈希值,不保留原始键值的大小关系,无法用于数据的排序操作
System.out.println("尝试对学生分数进行排序:");
Map<String, Integer> sortedData = hashIndex.entrySet().stream()
.sorted(Map.Entry.comparingByValue())
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, HashMap::new));
for (Map.Entry<String, Integer> entry : sortedData.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
System.out.println("由于哈希索引不支持数据排序操作,需要进行额外的排序操作。");
}
}
哈希索引中存放的是哈希值,并且不保留原始键值的大小关系,必须对数据进行额外的排序操作,性能会下降。
2.6 哈希索引不支持多列复合索引的最左匹配原则
对于复合索引,在计算哈希值时,哈希索引不是单独计算哈希值,而是先将组合索引键合并后,再一起计算哈希值。
所以,通过复合索引的前面一个、或几个索引键进行查询时,哈希索引也无法被利用。
示例:
创建一个哈希索引,存储了复合索引的数据,每个键都是由多个索引键组合而成,例如 “Alice_Math” 表示学生姓名和课程。
然后,我们尝试使用复合索引的前一个索引键(学生姓名)进行查询,以查找学生 “Alice” 的成绩。
import java.util.HashMap;
public class HashIndexCompositeKeyDemo {
public static void main(String[] args) {
// 创建一个哈希索引,存储复合索引的数据
HashMap<String, Integer> hashIndex = new HashMap<>();
// 插入一些复合索引的数据
hashIndex.put("Alice_Math", 85);
hashIndex.put("Bob_Math", 92);
hashIndex.put("Charlie_Science", 78);
hashIndex.put("David_Science", 95);
hashIndex.put("Eve_Math", 88);
hashIndex.put("Frank_Science", 89);
// 尝试使用复合索引的前一个索引键进行查询
// 由于哈希索引是基于合并后的键进行哈希计算,无法利用最左匹配原则
String searchKey = "Alice";
int searchResult = hashIndex.getOrDefault(searchKey, -1);
if (searchResult != -1) {
System.out.println(searchKey + " 的成绩为 " + searchResult);
} else {
System.out.println("未找到符合条件的记录");
}
System.out.println("由于哈希索引不支持多列复合索引的最左匹配原则,无法利用前一个索引键进行查询。");
}
}
由于哈希索引是基于合并后的键进行哈希计算的,无法利用最左匹配原则。
因此,我们无法使用哈希索引来执行这样的查询,需要检查合并后的键是否匹配,这可能导致性能下降。
以上,是哈希索引的 6 个局限性解析。
只回答这些,重点突出,次要带过,中规中矩,也是可以的。
但是,如果顺势再补充下哈希索引的使用场景,就会让面试官增加一些好感,觉得你的技术栈完整而扎实。
3. 哈希索引的应用场景
由于哈希索引自身的局限性,实际使用非常少。
哈希索引只适用于一些特定的场景,如等值查询频繁、数据分布均匀且内存充足的场景。
针对长字符串查询的优化,是哈希索引较为常见的使用场景之一。
示例:
数据库中保存了大量的 URL 信息,查询 URL 时,如果逐个字符去搜索,效率就很低。
这种情况就可以使用哈希索引。
- 给所有的 URL 计算一个 crc ,并保存起来;
- 对 crc 做哈希索引;
- 查询时,指定 crc 和 url ,快速定位到记录。
select * from url_info where crc = xxxx and url = "http://www.javamianshi.com"
执行这条语句时,
- 首先,针对 crc 查找哈希索引,找出所有 crc 值= xxxx 的记录,过滤掉大多数不符合条件的记录;
- 然后,再根据后面的 url 信息详细匹配。
通过哈希索引查询,查询的效率就很高了。
除此之外,哈希索引还可以应用于内存表、散列连接、等值查找等场景。
总结
本篇通过图解及代码示例,剖析了哈希索引的概念、 6 个局限性、4 个常见应用场景。
在 MySQL 中,哈希索引是一种以键-值(key-indexed)存储数据、基于哈希表实现的索引结构,只有精确匹配索引所有列的查询才能生效。
哈希索引相对紧凑的索引结构,赋予了它快速数据检索的能力。但是,哈希索引也有自身的一些局限性,例如哈希冲突、占用内存、不适用于范围及模糊查询等。
在实际环境中,哈希索引使用是非常少的。通常只适用于一些特定的场景,例如等值查询频繁、数据分布均匀且内存充足的场景等。
建议收藏备用,划走就再也找不到了。
大家好,我是爱分享的程序员宝妹儿,分享即学习。
如果觉得有用,请顺手【关注+点赞】支持下宝妹儿,拜谢。
PS.
本文已收录于宝妹儿精编的 2023版《MySQL 大厂高频面试题大全》PDF,,方便系统学习、面试通关。
《MySQL 大厂高频面试题大全》一共78页,50000多字,图文并茂,长期持续更新。
吃透它,足以应对 MySQL 面试。

– end –